
빅데이터 엔지니어는 대용량 데이터의 수집 가공 처리를 수행하는 빅데이터 플랫폼의 설계 구현 및 운영을 담당하는 기술자입니다. 빅데이터 엔지니어의 취업전망과 하는 일 그리고 필요역량에 대해서 정리해 보겠습니다.
빅데이터엔지니어
취업전망
특정 분야의 전망은 수요와 공급으로 예상해볼 수 있습니다. 시장이 성장하는 추세라면 해당 분야의 인력수요가 부족할 것이며 여기 종사하는 인력의 대우(=급여)도 자연히 좋아질 것입니다.
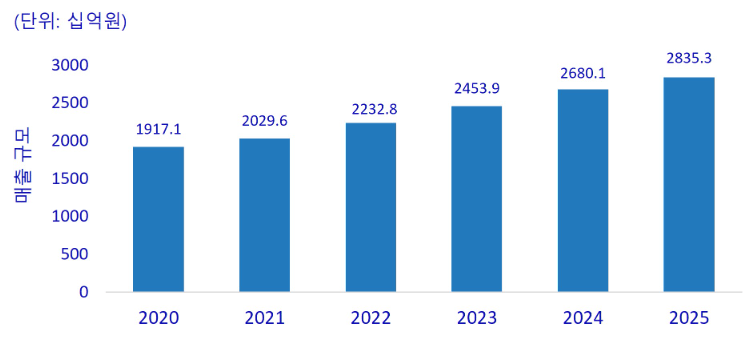
위의 그림은 2015년까지의 빅데이터 시장 매출 규모를 예측(IDC)한 자료입니다. 연평균 5% 이상 성장을 지속하고 있어 빅데이터 엔지니어에 대한 수요도 꾸준히 증가할 것으로 예상됩니다.
> 한번에 끝내는 빅데이터 처리 과정 (스파크, 하둡) 최저가 행사
하는 일
빅데이터 분야에 종사하는 기술 인력은 크게 3가지 부류입니다.
- Data Scientist
- Data Analyzer
- Data Engineer
이 중에 3번째 데이터 엔지니어에 해당하는 기술자의 경우 일반적인 소프트웨어 엔지니어의 업무에서 다음과 같은 빅데이터 관련 업무가 추가되는 경우가 많습니다.
- 빅데이터 플랫폼 구축
- 빅데이터 수집 및 처리 (정제)
- 데이터 분석 (통계, 머신러닝 등)
이중에 마지막 3번 업무를 깊이있게 다루는 사람은 ‘데이터 과학자’입니다. 따라서 데이터 엔지니어라면 1, 2번에 해당하는 빅데이터 플랫폼 구축, 개발, 운용 업무를 메인으로 담당할 가능성이 큽니다.
물론 위의 업무분류는 기업과 부서에 따라 유동적이므로 대략적인 참고자료만 활용해주시기 바랍니다.
필요역량
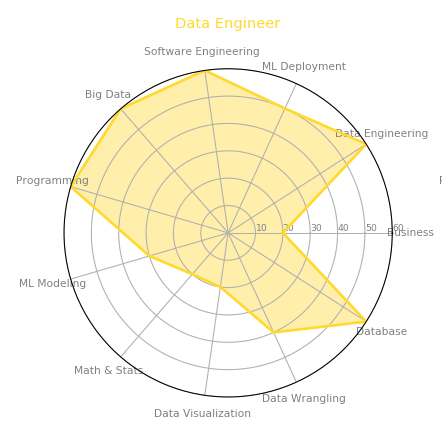
일반적으로 Data Engineer가 갖추어야 할 최소한의 필요역량은 아래 그림과 같습니다. 여기에 빅데이터의 처리에 필요한 플랫폼 지식이 포함되겠습니다. (e.g. 하둡 에코시스템)
1. Big Data 이해
빅데이터는 3V의 특징을 가지고 있습니다. 따라서 이를 수집, 처리, 분석하는데 필요한 프레임워크 또한 전형적 데이터 처리와 있습니다.
가령, 일반적인 정형 데이터 처리 시 전통적인 관계형 DB 모델을 많이 사용합니다. 하지만 빅데이터의 경우 텍스트, 오디오, 영상과 같은 비정형 데이터 유형을 처리해야 합니다. (Sqoop, Flume 등) 빅데이터 처리 플랫폼에 대한 내용은 아래의 이전 글을 참고 바랍니다.
| 정형데이터 | 비정형데이터 |
| 룰에 맞게 정해진 규칙에 따라 schema 정의가 가능한 데이터 형태. MS SQL, MySQL 등의 RDB에 최적화. (e.g. 나이, 성별, 주소 등) | 정해진 규칙이 없어 HBase, 카산드라, Mongo DB와 같이 NoSQL 기능을 지원하는 DB로 관리가 필요한 데이터 (e.g. 텍스트, 멀티미디어 데이터) |
2. 프로그래밍 스킬
빅데이터 플랫폼을 설계하고 구현하기 위해서는 하둡 에코시스템의 세부 구조를 이해하고 이를 유기적으로 동작시키기 위한 시스템 설계 기술이 필요합니다.
그리고 데이터를 수집, 분석하기 위해서는 파이썬이나(Panda, NumPy, Matplot) 자바, 자바스크립트와 같은 스크립트 기반 언어가 많이 사용되므로 이에 대한 프로그래밍 능력이 요구됩니다.
참고로 빅데이터 분석을 위한 파이썬기반 프로그램은 Anaconda 패키지를 많이 사용합니다.
3. SW Engineering
소프트웨어를 설계 구현 유지보수하기위해 필요한 기본적인 지식입니다. 컴퓨터 관련학과에서 ‘소프트웨어 공학’ 전공수업을 통해 배우는 역량으로 다음과 같습니다.
- SW 개발방법론
- 요구분석
- 설계(UML, 디자인패턴, Architecture)
- 테스팅 및 형상관리
4. 데이터 엔지니어링, DB 지식
기본적으로 데이터베이스(DBMS) 지식, 데이터 모델링, DB 최적화, SQL 질의를 통한 데이터 수집기술을 포함합니다. 위에서 살펴본 역량은 데이터 분석을 담당하는 엔지니어라면 기본적으로 가져야할 역량에 해당합니다.
컴퓨터학과를 전공하고 빅데이터를 전공한 경우라면 습득이 가능할 것입니다. 만약, 업무상 빅데이터 관련 교육이 필요한 경우 다음과 같은 다양한 무료 강의 사이트를 활용하여 기초지식을 습득할 수 있습니다.
추가역량 (업무에 따라 다름)
1. 머신러닝 개발
빅데이터의 분석을 위한 기술로 하둡의 머하웃이나 인공지능 프레임워크인 구글의 텐서플러, 파이토치와 같은 Framework 위에서 개발하기 위한 지식입니다.
만약 빅데이터 플랫폼의 설계 외에 데이터 분석까지 겸하게 된다면, 통계분석, 머신러닝 개념 및 프레임워크에 대한 이해 및 API를 이용한 데이터 분석기술이 필요합니다. (데이터과학자와 같은 역할)
2. 머신러닝 모델링
머신러닝 모델의 개념은 수많은 데이터 중에서 패턴을 발견하거나 기존의 데이터를 기반으로 미래를 예측하는 알고리즘을 의미합니다.
앞서 머신러닝 개발을 통해 구현을 완료하였다면 데이터 학습을 통해 모델링을 진행합니다. 이때 트레이닝 데이터 및 Validation Data의 추가 및 모델 최적화를 위한 다양한 파라미터 튜닝을 적용할 수 있습니다. 모델이 완성되었다면 이를 통해 데이터를 입력하고 이 모델의 accuracy 등을 평가할 수 있습니다.
3. 데이터 가시화 (Visualization)
R언어나 파이썬 기반 환경일 경우 Matplot 라이브러리 등을 통해 다음과 같이 도표나 그래프 등을 가시화 하는 것이 필요합니다. 보통 경영진 보고를 위해 자료를 만들거나, 데이터 분석 결과를 이해하기 쉽도록 하기 위해 사용합니다.
파이썬은 빅데이터의 분석 외에도 배우기 쉽고 활용할 수 있는 분야가 많아 업무자동화, 머신러닝, 웹개발 등의 다양한 분야에 활용되고 있습니다. 이와 관련한 무료 프로그래밍 강의 정보가 궁금하시며 아래를 참고 바랍니다.
이상으로 빅데이터 엔지니어의 전망 및 필요역량 등에 대해서 정리해보았습니다.