
빅데이터는 대규모의(Volume) 다양한(Variable) 데이터를 빠르게(Velocity) 처리하는 기술로 최근 AI 머신러닝과 결합하여 중요성이 커지고 있습니다. 빅데이터의 특징, 효율적 활용을 위한 주요 기술 및 산업분야 활용사례를 정리해보겠습니다.
빅데이터 특징
일반적으로 데이터 사이즈가 수십 테라바이트(TB) 부터 페타바이트(PB)를 넘어가기도 합니다. 이는 전통적인 RDB를(관계형 데이터 베이스) 통해서는 관리가 어렵습니다.
| 정형 데이터 | 비정형 데이터 |
| 사전에 모델이 정해져 있으며, 제한된 수의 데이터 format을 사용합니다. SQL 기반 관계형 데이터베이스를 사용하여 저장 및 검색이 가능하며 format이 정형화 되어 분석이 용이합니다. (예)주민등록번호, 차량 통행량, 1년 강수량, 기온변화 | 데이터 모델이 정해져 있지않아 매우 유연한 특징을 가진 질적 데이터입니다. 특정 스키마가 없는 NoSQA DB가 사용되며, 비정형 특성으로 검색이 어렵습니다. (예)텍스트(웹문서), 오디오/비디오 데이터. SNS 업로드 콘텐츠의 metadata (시간, 제목, 설명 등) |
또한 문자, 영상, 오디오와 같은 정형화되지 않는 특징도 가지고 있습니다. 이러한 대규모의 비정형화된 데이터를 수집, 저장, 분석, 처리하기 위한 빅데이터 기술을 자세히 알아보겠습니다.
빅데이터 주요기술
대량의 빅데이터를 효과적으로 수집 및 분석하기 위해서는 전통적인 데이터 처리기술과는 다른 방법이 필요합니다. 다음은 빅데이터 처리를 절차를 간략히 나타낸 그림입니다.
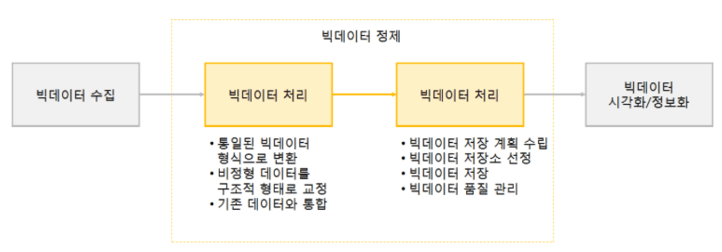
위의 그림과 같이 빅데이터 기술요소는 크게 수집, 처리, 분석 절차로 나누어볼 수 있습니다.
수집기술
여러개의 데이터 소스로부터 수동 또는 자동으로 수집하는 기술입니다. 비정형 데이터의 경우 정형데이터로 변환하여 정제 작업이 필요합니다. 대용량, 비정형 데이터를 분산 처리, 관리하기 위한 플랫폼으로 Hadoop, 스파크, 스톰과 같은 빅데이터 분산처리 플랫폼을 많이 사용합니다.
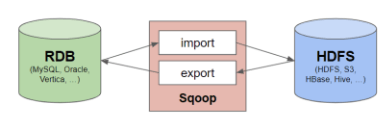
- Apache sqoop: 정형화된 SQL 데이터와 빅데이터(HDFS 파일시스템) 간의 양방향 전송이 가능합니다. (정형데이터 ⇔ 빅데이터)
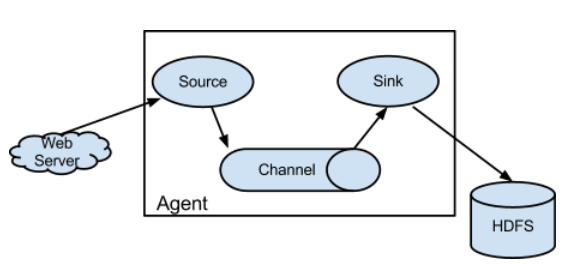
- Flume: 대량의 수집된 로그를 저장하고(Source, Channel) 지정된 외부 목적지로 전달하는 기능을(Sink) 가집니다.
- Scribe: 페이스북에서 개발한 데이터 수집 플랫폼으로 Flume과 유사하게 수집된 데이터를 HDFS 및 다른 저장소로 이동시킬 수 있습니다.
- Chukwa (척와): 분산된 서버에서 수집된 로그를 저장 및 분석하기 위한 도구로 실시간 분석이 가능한 장점이 있습니다. 수집된 로그는 HDFS를 이용해 저장합니다.
빅데이터 저장방식은 다음과 같이 크게 RDB, NoSQL, 분산파일 시스템으로 구분할 수 있습니다.
| 구분 | 특징 |
| RDB | 정형화된 관계형 데이터의 저장, 수정, 관리에 용이하며 SQL을 통해 이용한다. (Oracle DB, mySQL, MSSQL 등) |
| NoSQL | 비 관계형 데이터의 저장, 관리를 위해 사용하며 key-value, Document key-value, column 기반의 NoSQL을 주로 활용 (MongoDB, Cassandra, HBase 등) |
| 분산파일 시스템 | 분산된 서버에서 파일을 저장, 수정, 접근이 가능한 파일 시스템으로 TB ~ PB 단위의 대용량 데이터 처리에 적합 (HDFS: Hadoop File System) |
처리기술
수집된 데이터를 분석에 용이하도록 조작, 관리하는 기술로서 ETL, DM, 하둡(HBase) 기술 등을 이용할 수 있습니다.
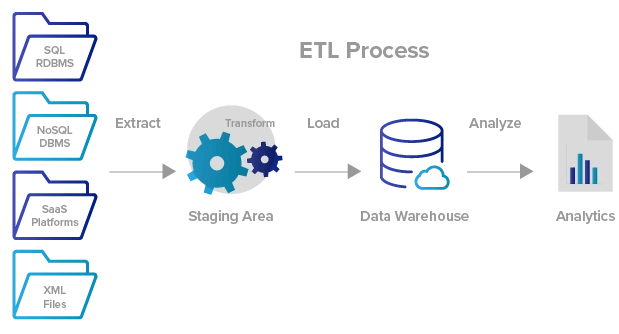
- ETL: 기업 Legacy DB를 분석 가능한 형태로 변환하여 데이터 웨어하우스(DW)에 전송하는 기술입니다. 아래 그림과 같이 추출, 변환, 적재의 과정을 통해 처리합니다.
- 하둡(Hadoop): 대량의 자료를 처리할 수 있는 분산소프트웨어 플랫폼으로 Apatch 프로젝트의 하나로 오픈소스로 개발되었습니다. Map reduced, HDFS, 카산드라와 같은 base platform 으로 구성됩니다.
- 스파크: 인메모리기반의 빅데이터 분산처리시스템을 반복되는 처리에 강한 특징을 가집니다.
- 스톰: 실시간 스트리밍 처리에 적합한 빅데이터 처리 기술입니다.
분석기술
수집된 빅데이터는 최종적으로 분석절차를 거처 부가가치를 만들어낼 수 있습니다. 전통적으로 통계적 분석기법, 데이터마이닝에 활용되었으며 최근에는 머신러닝, 인공지능으로 분석 기술이 발전하고 있습니다.
(1) 통계적분석
전통적 분석 방법으로 확률을 기반으로 예측하는 기법입니다. (상관분석, 회귀분석, 분산분석, 주성분 분석 등)
(2) 데이터마이닝
대량의 데이터 간의 패턴 및 상호 관련성을 분류, 추측하는 기술입니다. (예측, 분류, 군집화, 패턴분석, 시퀀싱 등)
(3) 머신러닝
대량의 데이터를 기반으로 지도, 비지도, 강화학습 방법을 통한 데이터 분석기술로 인공지능 분야의 한 종류입니다. (Tensorflow, 파이토치 프레임워크)
활용사례
최근 다양한 산업 분야(제조, 의료, 금융, 소매 등) 빅데이터를 활용하는 사례가 늘고 있습니다.
- 제조업: 과거의 ERP, MES, CMMS 등의 수 많은 데이터를 통합 관리하여 제조 프로세스를 개선하는 작업에 활용
- 의료: 유행성 질병의 발생 가능성 분석, 빅데이터를 통한 환자의 건강 상태를 예측, 추적관리
- 은행: 사용자의 과거 거래패턴을 통한 신용도 예측 (대출업무)
- 소매업: 빅데이터를 통한 시장의 수요 및 공급예측. 소비자 만족도 및 설문 조사 결과 분석을 통한 마케팅 전략에 활용
- 교육업: 과거 학습 이력에 따른 학습 결과의 분석 및 예측
- 여행업: SNS 분석을 통한 관광상품의 개발
- 정부: 지리정보, 공공정보의 분석 및 민간 개방
- 농업: 과거 날씨 및 수요예측. 기후데이터(센서)를 통한 수집 및 분석으로 최적의 농작물 생산환경의 설정
- 음식업: 내방 고객의 나이, 성별, 선호 메뉴 분석. 인터넷상 고객의 리뷰, 선호도 조사
이와 같이 수 많은 산업 분야에서 실제 빅데이터 분석기술을 통해 비즈니스에 활용할 수 있는 분야는 점차 확대되고 있습니다.